Prawdziwy cel wpisywania kodu CAPTCHA
Irytuje was wklepywanie kodu składającego się z niewyraźnych liter, za każdym razem gdy chcecie zarejestrować się na jakąś stronę? Jeśli robicie to korzystając z amerykańskich stron internetowych przyczyniacie się do zdigitalizowania tysięcy książek i publikacji znajdujących się w bibliotecznych archiwach.
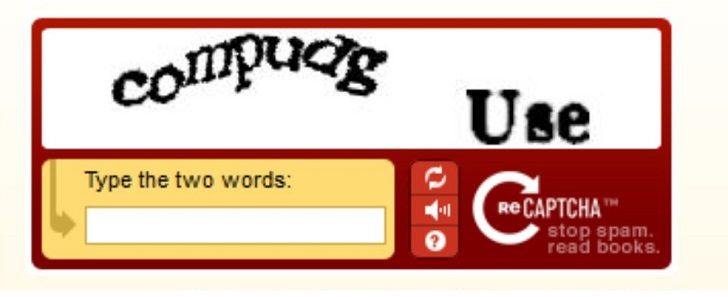
Obecnie ponad 40.000 stron internetowych – w tym Facebook – używa programu do ochrony o nazwie reCAPTCHA – to te sekwencje liter oraz cyfr, które musimy przepisywać żeby potwierdzić, że nie jesteśmy robotem.
System jest dziełem Luisa von Ahn, informatyka z Carnegie Mellon University w Pittsburghu, który pomógł opracować inny powszechnie stosowany system zabezpieczeń sieci zwany CAPTCHA, pozwalający ludziom na dostęp do witryny sieci Web tylko gdy udowodnią oni, że są człowiekiem, a nie botem stworzonym by zainfekować stronę.
Za każdym razem, gdy wpisujesz kod ukryty wśród rozmazanych znaków, dokonujesz czegoś niezwykłego, ponieważ pomimo 50 lat rozwoju informatyki, komputer w dalszym ciągu nie jest w stanie tego zrobić.
Problem polega na tym, że za każdym razem wpisując jedno z tych zniekształconych słów marnujemy czas. Von Ahn zbadał nawet dokładnie, ile czasu zostało zmarnowane w ten sposób przez ludzkość i uznał to za demoralizujące.
„Około 200 milionów kodów jest wpisanych codziennie przez ludzi na całym świecie. Za każdym razem tracą oni około 10 sekund swojego czasu” mówi von Ahn. „Jeśli pomnożyć te 200 milionów, można stwierdzić, że ludzkość jako całość marnuje około 500.000 godzin każdego dnia, wpisując irytujące zniekształcone znaki”.
Informatyk wpadł więc na pomysł jak kreatywnie wykorzystać zasoby naszych umysłów.
Wiedział, że biblioteki ponoszą ogromne wysiłki w celu digitalizacji swoich zbiorów. W pierwszej kolejności skanuje się książki lub gazety, następnie komputer wykonuje obraz każdego słowa i konwertuje je na tekst, stosując oprogramowanie do optycznego rozpoznawania znaków.
Maszyna często jednak natrafia na drukowane słowa, których po prostu nie może rozpoznać. Problem pojawia się szczególnie w przypadku starszych dokumentów, które zostały napisane przed 1900 rokiem, w których blaknie atrament, a strony stają się pożółkłe. Szacunkowo aż 20% wszystkich słów w digitalizowanych materiałach jest “nieczytelnych” dla maszyn.
W tych przypadkach do akcji musi wkroczyć człowiek odczytując te słowa. Von Ahn wpadł więc na pomysł aby połączyć ten proces z pracą programów zabezpieczających w Internecie. Zamiast prosić ludzi by kopiowali losowe ciągi zniekształconych liter i cyfr, można by zlecić im rozszyfrowanie tajemniczych słów ze zeskanowanych książek i gazet.

Swój pomysł wcielił w życie pod nazwą reCAPTCHA Project, współpracując z The New York Times, który digitalizuje gazety sięgając wstecz aż do 1851 roku oraz z organizacją non-profit Internet Archive, która zajmuje się digitalizacją książek.
W efekcie użytkownicy popularnych amerykańskich serwisów jak np. Ticketmaster (do zakupu biletów na eventy) czy Craigslist (odpowiednik Gumtree) przyczyniają się do digitalizacji zasobów bibliotecznych.
Użytkownicy dostają do wpisania dwa słowa – jedno jest faktycznie kodem zabezpieczającym, drugie nieczytelnym fragmentem książki. Problematyczny wyraz pokazany zostanie kilku użytkownikom, jeśli wszyscy zgodzą się co do jego znaczenia zostanie on włączony do cyfrowej kopii książki lub gazety.
“Liczba słów, którą do tej pory byliśmy w stanie digitalizacją jest szalenie duża – ponad miliard. Jak do tej pory dokładnie 1,3 mld” mówi von Ahn.
Naukowiec stwierdził, że tym sposobem w ciągu ostatniego roku Internauci przepisali tyle tekstu, by wypełnić ponad 17 600 książek, z dokładnością lepszą niż 99 procent.
Marc Frons, główny technolog operacji cyfrowych “The Times” również przyznaje, że tempo jest zadziwiające. Każdego miesiąca przekształcone zostaje około dwa lata zawartości gazet.
„W przyszłym roku, jeśli wszystko pójdzie dobrze, będziemy w stanie przerobić 70 kolejnych lat, co stanowiłoby całą resztę materiału, która nie jest jeszcze w zdigitalizowanym archiwum” mówi Frons.
Czy jednak nowy system nie zabiera użytkownikom jeszcze więcej czasu niż tradycyjne konfiguracje CAPTCHa? Wymaga by wpisać dwa kody a nie tylko jeden. Ale jak twierdzi von Ahn w praktyce szybciej idzie internautom wpisywanie angielskich słów niż losowych liter i cyfr.
Oczywiście może zdarzyć się, że natrafisz na słowo, które będzie zupełnie nieczytelne – np. zalane atramentem. Wtedy możesz spędzić nieco czasu główkując nad odpowiedzią, która być może jest niemożliwa do odczytu.
“Jeśli użytkownicy będą się denerwować nieczytelnymi słowami zawsze powinni mieć na uwadze, że tracą czas z dobrego powodu” podsumowuje von Ahn.
Źródła:
npr.org
cylab.cmu.edu















")













")




")
")



















